Fast Fashion, Big Data
A Deep Dive into the Predictive Analytic Techniques Employed by the Modern Fashion Industry Pertaining to Creative Considerations
Abstract
The early 2010s are largely recognized as formative years where the gradual introduction of data-driven decisions permeated retail and fashion industries. CEOs and CMOs of major fashion labels across the globe became accustomed to the concept of big data, yet only the mid-2010s saw the development of predictive techniques in the space.
This paper investigates key developments found in the fashion retail industry that advance the methodology behind creative considerations of predicting successful pieces that global and local audiences are likely to purchase. The paper introduces the concept of a ‘virtual designer’ methodology that enables rapid fabrication of textile concepts from start to finish. The paper also attempts to relate algorithmic implications to an industry where previously the focus of studies has centered around financial and sales forecasting for global fashion retailers.
Introduction
Fashion retailers and designer houses across the globe have been historically at odds with data-influenced decisions for many years prior to the mid-2010s. Their position is understandable given that a large majority of their business is distributing unique cultural capital amongst given populations. This cultural capital is intrinsically linked to the flourishing creative talent that each fashion house looks to employ, and few fashion executives view quantitative data as a means to accomplish creative goals and tasks.
A distinct paradigm shift occurred in the fashion industry once the distribution chains of retailers became increasingly global through the advent of fast, reliable internet. With consumers changing their purchase sentiments and becoming more comfortable with shopping online, e-tailers such as Amazon and AliBaba grew exponentially in just a few short years. These agile and data-heavy organizations used information passed onto them from consumers and merchandisers to make their business succeed online and offline. With fashion houses also operating in the retail industry, they had been left in the wake of the big data boom with little actionable items to solidify for future years to come. Yet they all had heaps of data they were sitting on, and it was only a matter of unlocking the value of the data¹ that the entire fashion industry was challenged with.
The early 2010s saw CEOs of major fashion houses also rebound from the global recession well, yet not quite to pre-2008 sales figures. GAP Inc., Zara, H&M, and each of their respective subsidiaries at the time appeared to be the only entities in the fashion industry ready to take on a new approach². Each of the aforementioned organizations sought to leverage big data in order to answer two key fashion retail questions:
- Can analytics provide creative direction to design processes in a predictive manner such that the organization can continue to grow sales?
- Can analytics predict distributed demand such that the organization can continue to grow sales?
The first question is the focus of this paper, answering some fundamental business questions for any fashion organization looking to utilize big data. However, the following caveats are to be considered when applying this project to any fashion association:
- The answer derived would be useful to the organization — it has the potential to maximize profits in a more efficient manner, creating design decisions that are founded in predictive consumer behaviour
- The difficulty of the answer is equal to the value of the answer
- The organization must be prepared to change and accommodate to the answer despite its disruption — particularly of importance when it comes to staffing creatives within the fashion label whose jobs would be at risk
- The level of analytic maturity is near the required sophistication (at least from large, fast-fashion retailers) to determine such a difficult answer
- Low hanging fruit has been used as testing ground for such a complex analytical implementation — this comes in the form of testing the project in local markets before rolling out globally
- There is currently a methodology measuring the success of the project — this would come in the form of examining the attribution of the new machine-generated designs to the incrementality of company sales
Rather than relying on the creative direction of their design teams, these select organizations look to replace artistic vision with the mining of data from first party datasets as well externally sourced information. However, they all face uncertainty in an industry moving away from mass production to the expectation of mass customization³. With social media and other products seemingly attempting to cater to an individual’s specific needs, the signals informing design decisions for successful production and distribution have to be rigorously tested to ensure a viable production cycle.
The following sections will cover how the systems implemented by the fashion industry in the mid and late 2010s answered the aforementioned retail questions, as well as discuss related work done in the field of big data pertaining to informing creative direction for fashion brands at a global scale.
Literature Review
Given that major fashion retailers are dependent on sales of their goods as their primary revenue source, studies surrounding the amplification and prediction of sales has largely been the focus of academic interest over the years. Particularly when evaluating the feasibility of advanced analytics⁴, the organization funding the research is looking to obtain a direct return on its investment in the form of aggregate retail sales. To date, there are only a handful of publications from both academic and non-academic organizations discussing the implications of big data on the creative departments within a fashion retailer’s operational structure.
One of the most extensive works going beyond the sales focus of fashion retail is one book from Sebastien Thomassey and Xianyi Zeng titled Artificial Intelligence for Fashion Industry in the Big Data Era⁵. It provides a comprehensive overview of the fashion industry in relation to design, manufacturing, supply, and retailing operations. In particular, focus is drawn to the implications of machine learning on garment selection, manufacturing, and discrete event simulation modeling optimized for textile production. This 2018 publication marries perfectly with another whitepaper presented by Jain, Zeng et. al titled Big Data in Fashion Industry from the 17th World Textile Conference AUTEX⁶. It serves as the foundation of the virtual style advisor recommender concept this paper will be building on later. This publication is the cornerstone for modern applications of data-driven decision making for today’s fashion houses, including all facets of consideration ranging from material selection to technical production and design. Additional readings from Beheshti-Kashi et. al gloss over the influence of social media analytics in the big data boom⁷. However, implications from this publication are not wide-reaching enough for the purposes of creating a closed-loop predictive environment of design and production within a fashion organization. A more selective reading on technical production can be found in the form of AI for Apparel Manufacturing in Big Data Era: A Focus on Cutting and Sewing⁸ from Xu et. al, with a focus on automation and data extraction for cutting, sewing, finishing, and packing activities.
Methodology and Challenges
In order to best anticipate what automatically generated creation consumers will purchase from a fashion label, a combination of previously researched solutions surrounding recommender systems will have to be implemented. Signals from various data sources (of which will be discussed in section 4) will inform the creative process of steps to partake in when creating a product that consumers themselves don’t know they want yet. Previous research from Park et. al showcases recommender systems where collaborative filtering allows a recommender system to function on the selected preference(s) derived from a group of users⁹. This allows for user profiles to be matched to an item’s attributes via a user-driven rating system of items and their attributes.
The challenge in these recommender systems is found in the fact that they have a “cold start” built in. Essentially, the recommender will struggle to provide a recommendation to a new user in the absence of user data and item ratings. Only with added information in copious amounts can the system begin to come to some interpretations of the user’s preferences in a quantitative manner.
Park et. al were able to overcome the “cold start” problem through the implementation of knowledge-based recommender systems. These are recommender systems of the form where databases linked to other databases inform complex relationships of new users without the need of user profiles and ratings. In the implementation of these systems for fashion labels, these require large amounts of data particular to the fashion industry, as well as qualitative information that can be translated for the system to interpret mathematically.
A prime example of research conducted into fashion-oriented knowledge-based recommenders originates from Wang et. al¹⁰. The team investigating fashion-oriented knowledge-based recommenders was particularly interested in advancing the “cold-start” solution by analyzing the perception of fashion experts and consumers on a large number of attributes. This included analysis of emotional fashion themes in relation to human perception of personalized body shapes and their respective garment selection. While the study employed fuzzy decision trees to empirically model a relationship between human body measurements and sensory descriptions, it also employed fuzzy cognitive maps to analyze the relationship between sensory descriptions and overarching fashion themes. In an ensemble environment, the combined models were able to create a recommender system that more effectively evaluated if a body shape is of importance — and compatible — to a desirable fashion theme.
Common Data Considerations in the Global Fashion-Industry
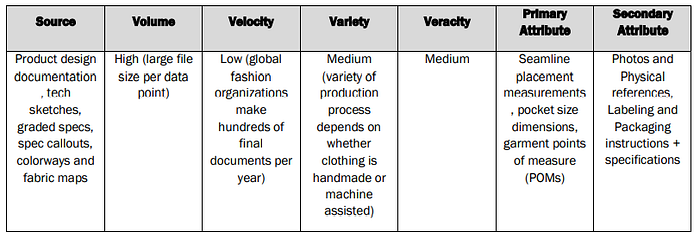
In order to begin creating the aforementioned recommender systems, an organization must first identify the required forms of data for undertaking such a project. Within the context of big data in the fashion industry, the primary datasets under observation for knowledge-based recommender models flow from 5 different data sets: Material data, Fashion Design data, Body data, Color data, and Technical/Production design data. Below are some guidelines for each data type and its considerations.
- Material Data: This data primarily constitutes the type of fabric that is used to construct a particular fashion item or piece.
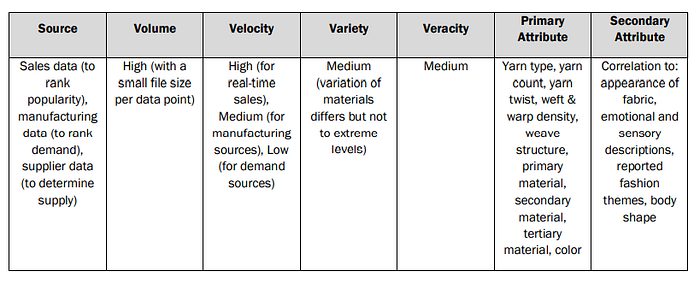
- Fashion Design Data: This data constitutes the documentation and classification of the elements & principles of design that have been sourced to classify the design of a particular fashion product.
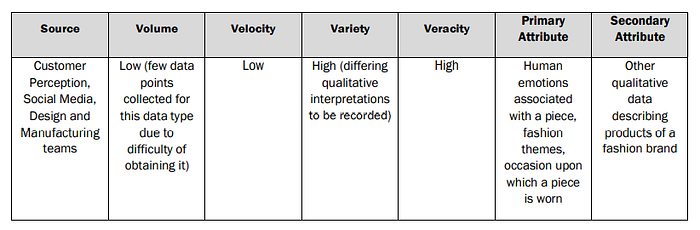
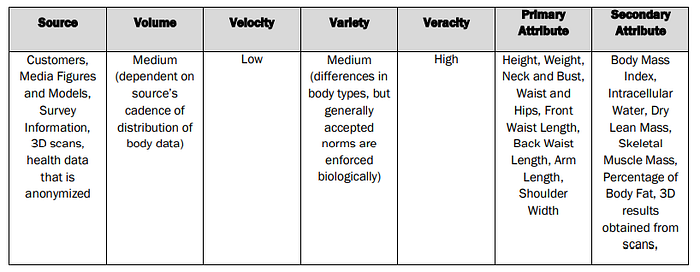
- Body Data: This data includes body data for local and global markets of customers observed in retail locations, influencers, models/celebrities wearing the pieces sold, and customer survey information collected by the fashion organization. It may come in the form of quantitative measurements (2D measurement as it is often referred to, using conventional metrics) as well as in a 3D form which utilizes 3-dimensional body scanners for a more representative body image transcription.
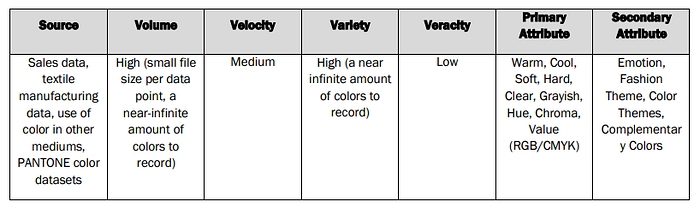
- Color Data: This category is self-explanatory but differs in that additional attributes are collected about the color prominence within the fashion industry. It typically utilizes the 1991 version of Kobayashi’s color image scale which classifies colors as warm or cool, soft or hard, clear or grayish¹¹. These are then correlated with hue, chroma, RGB/CMYK color values, and interpreted emotions derived from color.
- Technical Production & Design Data: This dataset focuses on the technical specifications required for making a particular piece. It mainly is derived from data obtained from manufacturing partners and vendors as well as internal production teams.
Additional Data Considerations
In addition to the aforementioned data sets, recommender models would also likely be ingesting Google Analytics, sales and customer CRM data, as well as social media feed data in conjunction with Google trends data.
When analyzing considerations for data collection and storage, enterprise cloud solutions are some of the most viable for the fashion industry’s organizations. Products such as Amazon S3 Intelligent-Tiering — with one tier optimized for frequent access and another cost-efficient layer optimized for more rare computations — can be perfect given that the volume, velocity, variety, and veracity of data are all different for the datasets mentioned in this section.
Such a project undertaking is not only going to be structurally demanding at the local level, but this will be compounded even more at the global enterprise level. When discussing data management considerations, data retention within the organization will need to follow a very strict policy given the amount of varied data being ingested. Some data management guidelines that can be recommended for fashion organizations are:
- Maintain a 5–10 year holding period of structured, transactional data (inclusive of CRM data)
- Maintain a 1–3 year holding period for trends data used in predictive modeling
- Maintain a 3–5 year holding period for trends data used in qualitative analysis for lower-level creative designers
- Maintain a 90–120 day holding period for category specific trend data used in data ingestion and ETL
- Engage in a backup audit on an annual basis to clean duplicates and inactive data sets to keep cloud costs low
- Conduct continuous privacy and security checks with vendor teams at Amazon (or whatever cloud service is chosen) to ensure data integrity, customer privacy, DDoS mitigation, data encryption capabilities, monitoring and logging of file changes, and comprehensive access controls to project-scoped individuals
- Ongoing verification of local compliance requirements across active markets
Proposed Methods of Improvement
Building off Jain, Zeng et. al’s research into recommender models that bypass the “cold-start” problem, the idea of a virtual designer has come into prominence in 2018 and 2019. The proposed idea of a virtual designer lies in taking Wang et. al’s research of knowledge-based recommenders and fusing them with the functionality of a search engine that the model can crawl.
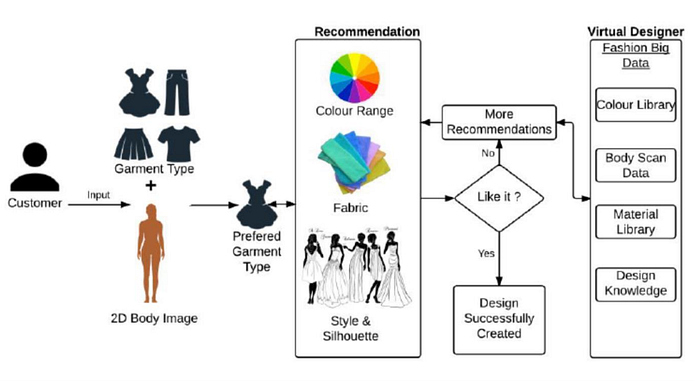
This firstly includes the organizational structure of fashion data that acknowledges a level of interactivity between the aforementioned data sets and their respective data types. When presenting a structure of the datasets shown in section 4, we are able to visualize a knowledge base that looks something like the figure shown below.

It is also worth noting that the implementation of virtual designer systems is mostly restricted to the online digital space at the moment. A live implementation of a more simple virtual designer within the online retail space exists in the United States’ Nike.com/NikeLab — a tool which allows users to customize their shoes how they see fit, with recommendations of similar procedurally-generated designs delivered to the user’s profile once sufficient information is provided to the recommender.
The focus of advancing this technology is allowing users working in fashion industries to select basic parameters which then serve as a basis for the system to generate a final recommendation. By eliminating the “cold start”, users can also request randomized inputs to generate an output. For new proposed iterations of virtual designers, the systems are optionally programmed to include user input in the form of keyword queries that assist the recommender system in classifications of results. This enables tagging of outputs to associate custom user keywords to generated outputs often strictly for organization purposes.
The recommender begins firstly by prompting an initial selection of 2 primary parameters which fuel the process: garment type and 2D body image. Note that this does not need to be an actual image, it is synonymous with the dimensions of height, weight, and optionally, sex. Given the aforementioned ingested data, the system is able to determine a preferred garment type for processing an output.
In terms of data analysis, the proposed systems are expected to function using Clusters Classification Decision Support System (DSS). Fashion retailers are able to use DSS systems to import mined and ingested data into several main components: file drawer systems, data analysis systems, analytical information systems, representational models, optimization models, and suggestion models. From here, clustering of the ingested data is meant to inform similar relationships found in color, fabric, style, and silhouettes. Enhanced K-Means algorithms¹² for clustering can be employed for grouping fashion attributes by changing centroid points from random points to center points of data. This includes starting with the center points of data sets, calculating the distance between data samples and clusters, assigning data samples to the closest cluster center, then calculating the new cluster center. This ensures no cluster objects move groups and avoid the creation of empty clusters, providing clear classifications of fashion attributes ingested and their similar relationships.
The result of the recommender is an output of two forms depending on the complexity of the ensemble:
- Output 1: Algorithmically generated images of clothing with embedded tags showcasing influencing factors. This utilizes a generative adversarial network (GAN) to synthesize artificial images. An organization can use StyleGan generation to transform identified and tagged emerging fashion styles into input vectors and generate intermediate vectors.
- Output 2: Descriptive text based on judgment outputs originating from a random forest to determine the type of assortment to be produced. This output is less likely to be used in a retail medium where a visual response is preferred from consumers and is more akin to academic settings.
Given the output from the recommender, the user may be prompted to save the creation or, if dissatisfied, generate a new creation with additional data attributes stored in the cloud. The system will then repeat the analysis process, only now with additional variables of color, body data, materials, and production/design specifications. A revised output is generated once more, and if a prompt for additional processing is mandated, the iterative cycle begins again ad infinitum (or until data points are exhausted).
Organizational Implications
With these systems enabling fashion houses to create designs within milliseconds based on two primary attributes, organizations that function in the industry must pivot on several key operational aspects.
- Deciding on a myriad of designs: The system ultimately outputs an item that is data-driven and most likely to do well in a retail environment. If thousands of such models can generate pieces in under an hour, how does the output of these systems influence decision making in fabric production? Organizational leads on such a project will need to carefully examine the embedded data of the model and ensure high transparency for senior leadership teams to make these decisions. The purpose of analyzing the sources influencing outputs will be contingent on the fashion business’ goals for a particular run or season. Given that profit maximization is a key driver behind such projects, items generated that are estimated to produce the most sales will be given priority to others that rank highly in emotional response or quirkiness.
- The Impact of Hyper-Customization on Manufacturing Partners: With an increased output of designs coming from a fashion label, the design and production techniques required of manufacturing partners may be heavily impacted. If recommender systems predict to a high degree of accuracy that clothing of a particular type is more profitable than previously manufactured items, this requires manufacturers and suppliers to adapt their stock without delay. Hyper-customization on a mass scale is the ultimate goal of projects like these, enabling users online to create their own clothing in a matter of seconds. With such a variety of clothing attributes associated with any particular piece, manufacturers and suppliers will need to work together more closely than ever to ensure just-in-time production processes are genuinely followed as orders come in.
- The Impact of Hyper-Customization on Consumer Markets: In addition to disrupting the manufacturing and supplier chain of operations, a highly effective recommender system is also capable of shaking up consumer perceptions of clothing and its respective exclusivity. Given that mass customization is possible with such systems, consumer markets may react by either increasing the value of unique items or decreasing them if their volume becomes too excessive. In the luxury fashion industry, such a recommender system coupled with exclusivity of purchases could drive up prices of pieces astronomically. Another consideration for fashion piece valuation would also be in the quality of the final products and organizations’ respective quality control — something that is beyond the scope of this paper.
Conclusions and Future Considerations
Moving into an era of data-driven design is something that the fashion industry will find incredibly controversial. Currently, the aforementioned applications of such technology remains limited to the forefront of fast-fashion retailers — those that rely solely on volume and not artistic intent to drive their organizations’ success. Disruption will be inevitable, however, decision-makers will continue to exist as guardians of what a fashion brand truly stands for. Even if recommenders are able to deviate from a brand’s norms, limits can be set on the model such that a particular aesthetic appeal and emotion can be consistent in generated outputs. As of 2021, few organizations in both the luxury and non-luxury space have the analytical maturity to take on such complex projects. They require enormous amounts of data, high standards of data management, and staffing to ensure quality of the models and their maintenance. This amounts to a stack of operational luxuries that many fashion retailers simply do not have. For the immediate future, we will continue to see most fashion retailers use vendor-sourced BI tools for their quasi-predictive gut-checks. These include¹³:
- Spate: Currently in private beta, it uses online behavioural signals to predict trends in food, beauty and fashion.
- MakerSights: Correlates consumer feedback with historical sales data to inform product development.
- Google Trends: Shows historical search interest on any keyword, sorting by date, category and geography.
- Edited: Provides real-time retail data, such as what is being stocked and what is sold, from brands around the world.
- NextAtlas: Detects emerging trends from social media influencers.
- Pinterest: Advertisers can access insights about what customers are interested in based on their Pinterest behaviour.
Works Cited (Non-Alphabetical)
- Manyika J, Chui M, Brown B, Bughin J, Dobbs R, Roxburgh C, Byers AH. Big data: The next frontier for innovation, competition, and productivity
- Israeli, Ayelet, and Jill Avery. “Predicting Consumer Tastes with Big Data at Gap.” Harvard Business School Case 517–115, May 2017. (Revised March 2018.)
- De Raeve A, De Smedt M, Bossaer H. Mass customization, business model for the future of fashion industry. In3rd Global Fashion International Conference 2012 Nov (pp. 1–17).
- Alon, I., Qi, M., & Sadowski, R. J. (2001). Forecasting aggregate retail sales: a comparison of artificial neural networks and traditional methods. Journal of Retailing and Consumer Services, 8(3), 147–156. http://doi.org/10.1016/S0969- 6989(00)00011–4
- Thomassey, Sébastien & Zeng, Xianyi. (2018). Artificial Intelligence for Fashion Industry in the Big Data Era. 10.1007/978–981–13–0080–6
- Jain, S. (2017) Big data in fashion industry In: IOP Conference Series: Materials Science and Engineering: 17th World Textile Conference AUTEX 2017- Textiles — Shaping the Future, 152005 IOP Conference Series: Materials Science and Engineering https://doi.org/10.1088/1757-899X/254/15/152005
- Beheshti-Kashi S., Lütjen M., Thoben KD. (2018) Social Media Analytics for Decision Support in Fashion Buying Processes. In: Thomassey S., Zeng X. (eds) Artificial Intelligence for Fashion Industry in the Big Data Era. Springer Series in Fashion Business. Springer, Singapore
- Xu Y., Thomassey S., Zeng X. (2018) AI for Apparel Manufacturing in Big Data Era: A Focus on Cutting and Sewing. In: Thomassey S., Zeng X. (eds) Artificial Intelligence for Fashion Industry in the Big Data Era. Springer Series in Fashion Business. Springer, Singapore
- Park DH, Kim HK, Choi IY, Kim JK. A literature review and classification of recommender systems research. Expert Systems with Applications. 2012 Sep 1;39(11):10059–72
- Wang LC, Zeng XY, Koehl L, Chen Y. Intelligent fashion recommender system: Fuzzy logic in personalized garment design. IEEE Transactions on Human-Machine Systems. 2015 Feb;45(1):95- 109
- Kobayashi S. Color image scale. Kodansha Amer Incorporated; 1991
- Elseddawy, Ahmed. (2013). A Proposed Data Mining Technique to Improve Decision Support System in an Uncertain Situation. International Journal of Engineering Research and Development. 8. 56–61
- McDowell, Maghan. “Analytics are reshaping fashion’s old-school instincts.” Vogue Business, Vogue, 7 Feb. 2019, www.voguebusiness.com/technology/data-trend-forecasting-google-tracking-tools
