Natural Language Processing for Marketing and E-Commerce Using spaCy
A guide on how to parse landing pages, scan for lexical elements, and implement them in your marketing and e-commerce initiatives.
Preface
In my previous article, I discussed the possibilities of Google Ads Responsive Search Ad copy automation using Python 3 and Pandas. This time around, I will be presenting a guide on how to extract webpage-specific lexical information using natural language processing (NLP) for additional copy considerations. The NLP program featured in this article will allow you to:
- Parse a webpage for text and lexical elements
- Determine a webpage’s subject through its lexical elements
- Present the most appropriate lexical elements for copy generation
We will conclude our learnings by integrating our extracted lexical elements into our previously constructed Responsive Search Ad generator.
Note: the lexical information we will be extracting can also be considered for A/B testing in an e-commerce environment — an upcoming publication will cover the process behind that. For now, add me on LinkedIn if you would like to follow all my new projects.
Project Dependencies
This program requires several libraries to function efficiently. We begin with a brief description of each library along with their respective installation instructions.
$ pip install requests
import requestsThe requests module allows you to send HTTP requests using Python. The HTTP request returns a Response Object with all the response data (content, encoding, status, etc).
$ pip install justext
import justextjusText is a tool for removing boilerplate content, such as navigation links, headers, and footers from HTML pages. It is designed to preserve mainly text containing full sentences and it is therefore well suited for creating linguistic resources such as Web corpora.
pip install -U pip setuptools wheel
pip install -U spacy
python -m spacy download en_core_web_trfimport spacy
from spacy.matcher import Matcher
spaCy is a free, open-source library for advanced Natural Language Processing (NLP) in Python. spaCy is designed specifically for production use and helps you build applications that process and “understand” large volumes of text. It can be used to build information extraction or natural language understanding systems, or to pre-process text for deep learning. The Matcher module lets you find words and phrases using rules describing their token attributes.
Note: We will be using the en_core_web_trf pipeline for more accurate results (as opposed to the more common and performance-oriented en_core_web_sm variant).
from collections import CounterCounter is a dict subclass for counting hashable objects. It is a collection where elements are stored as dictionary keys and their counts are stored as dictionary values. Counts are allowed to be any integer value including zero or negative counts. The Counter class is similar to bags or multisets in other languages.
Text Extraction
This program aims to extract lexical elements from any given URL where access to the requested resource is not forbidden. If you are attempting to request a webpage’s resources that are blocked for security purposes, you will likely encounter a 403 error. If you wish to deploy this program on an enterprise level, you will need to consult with your IT department to determine whether a security exemption for your API calls is feasible.
For our example, we will be analyzing a product landing page from Whirlpool’s Canadian appliance assortment.

This is quite a low-level page on Whirlpool’s webpage hierarchy, so why are we analyzing this one? In practice, it is much harder to correctly identify the subject of a low-level landing page as opposed to a high-level one — this is usually due to the lack of textual content on low-level pages. If we can get accurate results at a granular level, the program will scale to more generic landing pages with ease.
We begin by sending an HTTP request to our target landing page using the requests module.
#extract texturl = "https://www.whirlpool.ca/en_ca/laundry/washers/he-top-load-washer/p.5.5-cu.-ft.-i.e.c.-smart-top-load-washer.wtw6120hw.html?originVariantsOrder=WH,C6"
response = requests.get(url)
The jusText library is required to extract the text elements of the webpage. jusText will remove the surplus “clutter” (boilerplate, templates) around the main textual content of a web page and return the textual elements.
paragraphs = justext.justext(response.content, justext.get_stoplist("English"))Each paragraph parsed by jusText will be appended to a list — in this case, it is an empty list named for_processing. The list is subsequently joined into a single string for spaCy parsing.
for_processing = []
for paragraph in paragraphs:
if not paragraph.is_boilerplate:
for_processing.append(paragraph.text)for_processing = ''.join(for_processing)
Lastly, view the extracted contents in the terminal by printing the list.
#print(for_processing)Extract All Part-of-Speech (POS) Tags
Lexical elements can also be referred to as Part-of-Speech (POS) tags. To parse the extracted text for POS tags, we begin by loading the en_core_web_trf pipeline using spaCy.
nlp = spacy.load('en_core_web_trf')We will also initialize doc , a container for accessing linguistic annotations. In our scenario, doc will be assigned to the values of for_processing .
doc = nlp(for_processing)Each POS within for_processing will need to be broken down into separate words, punctuation, etc. known as ‘tokens’. This process is called tokenization and spaCy will accomplish this by applying rules specific to the language we are working with. We’ve loaded the en_core_web_trf pipeline for our project, meaning the rules applicable to tokenization will be specific to the English language.
You can view the values of each POS by printing them. Our landing page has too many POS tags to reasonably display — I will show only a small example of the tokenization results.
for token in doc:
print(token.text, token.pos_)OUTPUT
Wash PROPN
technology NOUN
with ADP
Active PROPN
Bloom PROPN
™ PUNCT
wash NOUN
action NOUN
senses VERB
the DET
Every token is assigned a POS Tag in spaCy from the following list:
Viewing all POS tags is not entirely useful on its own, but we’ve now completed the first objective of our program.
- Parse a webpage for text and lexical elements (Done!)
Let’s see how we can apply our POS tags to a practical example.
Determine a Webpage’s Subject and Entity
If we were to create marketing materials specific to a webpage, we ought to:
- Be able to parse our webpage for its primary topic and entity
- Extract descriptive tokens (adjectives) directly related to our primary topic
- Utilize the most appropriate adjectives for use in our marketing activations
Let’s first figure out what our webpage is about. We’ll do this by taking a look at three separate frequency metrics — frequency of general tokens, frequency of nouns, and frequency of proper nouns.
We begin by creating a list of all our webpage’s tokenized elements that may be considered “words” — ie. tokens that are not stop words or punctuation.
nlp = spacy.load("en_core_web_trf")
matcher = Matcher(nlp.vocab)
doc = nlp(for_processing)# all tokens that aren't stop words or punctuationswords = [token.text
for token in doc
if not token.is_stop and not token.is_punct]
Let’s display our top 5 most frequently observed “word” tokens.
# display the five most common tokensword_freq = Counter(words)
common_words = word_freq.most_common(5)
print(common_words)OUTPUT
[('\n', 43), ('washer', 15), ('5', 12), ('load', 10), ('water', 9)]
It looks like there are a lot of newlines or line breaks on our page. There’s also a value of ‘washers’ (that’s a good sign), as well as a few other digits and nouns.
That’s a good start — let’s try identifying the most common nouns now. By focusing strictly on nouns, we should be able to replicate a hierarchy similar to what was observed in common_words , with the added benefit that we can be sure the token is a class of people, places, or things.
# noun tokens that aren't stop words or punctuationsnouns = [token.text
for token in doc
if (not token.is_stop and
not token.is_punct and
token.pos_ == "NOUN")]
We now display the 5 most frequently observed nouns. We will also assign our most common noun to most_common_noun for later use.
# display the five most common noun tokensnoun_freq = Counter(nouns)
common_nouns = noun_freq.most_common(5)
most_common_noun = str(common_nouns[0][0])
print(common_nouns)
print("The most common noun is:", most_common_noun, "or", most_common_noun.capitalize())OUTPUT
[('washer', 15), ('load', 10), ('water', 9), ('account', 9), ('information', 7)]The most common noun is: washer or Washer
We now have identified the most commonly referenced person, place, or thing on our webpage. Given the information we have available to us, we will make the assumption that this is the topic of the webpage.
Notably, this result is highly contingent on the content associated with the webpage — if a webpage does not have sufficient textual content drawing attention to its primary subject, the most common noun may prove to be completely unrelated to its true subject.
What if we tested our extracted text for proper nouns ? These are nouns that designate a particular being or thing, typically using a name. Let’s try using this approach to attempt to establish the brand of our identified washer.
# noun tokens that arent stop words or punctuationsnames = [token.text
for token in doc
if (not token.is_stop and
not token.is_punct and
token.pos_ == "PROPN")]# five most common proper noun tokensname_freq = Counter(names)
common_names = name_freq.most_common(5)
print(common_names)OUTPUT
[('Privacy', 5), ('Notice', 4), ('Load', 4), ('Wash', 4), ('Terms', 3)]
Unfortunately, those results don’t look quite right. Due to the lack of textual content mentioning our brand name, our program is unable to identify that this “washer” is in fact a “Whirlpool washer”. There is another way we can solve our problem — using spaCy’s named entity recognition function. As per spaCy’s documentation:
spaCy can recognize various types of named entities in a document by asking the model for a prediction. The default trained pipelines can identify a variety of named and numeric entities, including companies, locations, organizations and products.
Named Entity Recognition (NER) categories can fall under the following labels:
Since we solely want to identify an organization/brand, we will specify this via if (ent.label == ‘ORG')in our NER run below.
# attempt named entity recognitionentities = [ent.text
for ent in doc.ents
if (ent.label_ == 'ORG')]
Note that domains will also be categorized as organizations — we’ll proactively proceed to remove domain suffixes from our entity recognition list.
entities = list(map(lambda x: x.replace('.com','').replace('.ca',''), entities))Now let’s display our results in the same format as before — print the five most frequently observed entities.
# display the five most common entitiesent_freq = Counter(entities)
common_entities = ent_freq.most_common(5)
print(common_entities)OUTPUT
[('Whirlpool', 3), ('AccountWhirlpool', 1), ('Whirlpool Canada', 1), ('emailWhirlpool Canada', 1), ('Home Depot', 1)]
Looks like the NER worked — we now know the brand that is most frequently observed on our respective webpage. Given our available information, we can assume this is the brand of our previously identified washer. Let’s assign this newly identified brand to most_common_entity for later use.
most_common_entity = str(common_entities[0][0])To summarize, so far we have determined:
- The subject of our webpage — identified by spaCy as “washer”
- The brand/organization of our washer — identified by spaCy as “Whirlpool”
Relevant Descriptions and Sentiment Analysis
We can already describe our washer as a Whirlpool washer, but what if we were to find additional descriptive words in the form of adjectives rather than entities?
We could pull an entire list of adjectives found in our webpage, but that would require a lot of manual work in creating noun, adjective pairs — some of which wouldn’t even be of interest to us.
Luckily, spaCy’s matcher module allows us to find the instances of adjectives in our webpage that are adjacent to our previously identified webpage topic. We express this adjacent relationship using a pattern — “find me all instances of POS tags that are adjectives that are immediately followed by the most commonly identified noun, “washer”/”Washer”.
nlp = spacy.load("en_core_web_trf")
matcher = Matcher(nlp.vocab)
doc = nlp(for_processing)pattern = [
[{"POS": "ADJ"}, {"TEXT": most_common_noun}],
[{"POS": "ADJ"}, {"TEXT": most_common_noun.capitalize()}]
]
matcher.add("ADJ_NOUN_PATTERN", pattern)
matches = matcher(doc)
We saw in our earlier noun detection algorithm that 15 instances of “washer” were found in our webpage — let’s display the results of our match and see how many instances with our superimposed pattern are returned.
print("Total matches found: ", len(matches))OUTPUT
Total matches found: 3
There are three instances in the textual content where our pattern matches. Let’s view the noun-adjective pairs and assign them to the relevant_adjectives variable.
relevant_adjectives = []
for match_id, start, end in matches:
relevant_adjectives.append(doc[start].text)
for match_id, start, end in matches:
print("Match Found: ", doc[start:end].text)print("The relevant adjectives are:", relevant_adjectives)OUTPUT
Match Found: smart washer
Match Found: Best washer
Match Found: smelly washer
The relevant adjectives are: ['smart', 'Best', 'smelly']
spaCy was able to recognize smart, Best, and smelly as adjectives related to our most_common_noun. That’s a start…however, “smelly” doesn’t exactly sound like an adjective that you’d want to describe this washer with — especially in marketing materials.
We can conduct sentiment analysis on the associated adjectives to determine whether they have a “positive” connotation or a “negative” one. To do this, we’ll be importing the TextBlob library.
TextBlob is a Python (2 and 3) library for processing textual data. It provides a consistent API for diving into common natural language processing (NLP) tasks such as part-of-speech tagging, noun phrase extraction, sentiment analysis, and more.
$ pip install -U textblob
$ python -m textblob.download_corporaThe procedure is straightforward — for each adjective in our previously defined relevant_adjectives , we will use TextBlob to analyze the adjective’s sentiment, and subsequently display its polarity and subjectivity scores.
Note: Polarity is represented as a floating point range where a polarity score of 1.0 indicates absolute positivity and a -1.0 polarity indicates absolute negativity.
Note: Subjectivity is represented as a floating point range where a subjectivity score of 1.0 indicates the meaning is open to infinite interpretability and a -1.0 polarity indicates impartial and objective meaning.
Once our scores our analyzed, we instantiate a variable named positive_adjectives to store adjectives that pass a conditional argument whereby only adjectives with positive polarity values are accepted.
#conduct sentiment analysis (1.0 polarity = positive, -1.0 polarity = negative)from textblob import TextBlobpositive_adjectives = []
for adjective in relevant_adjectives:
print(adjective, TextBlob(adjective).sentiment)
if TextBlob(adjective).sentiment.polarity > 0:
positive_adjectives.append(adjective)
print("The positive adjectives are:", positive_adjectives)OUTPUT
smart Sentiment(polarity=0.2, subjectivity=0.6)
Best Sentiment(polarity=1.0, subjectivity=0.3)
smelly Sentiment(polarity=0.0, subjectivity=0.0)The positive adjectives are: ['smart', 'Best']
Putting It All Together — Automating Your Copy
In my previous article, I presented a step-by-step guide on how to create an ad copy automation tool in Python with direct .CSV output, formatted for compatibility with Google Ads and Microsoft Ads platforms.
We will use the lexical elements we’ve extracted from our webpage to generate ad copy without having to manually decide the product, brand of product, and the product’s relevant adjectives. I will not be reproducing all the code I’ve written in my previous article — if you would like to create your own customized program, you can find the full code at my gitHub repository.
I’ve modified the original source code of the Python Responsive Search Ads program to make it relevant to our current e-commerce Whirlpool example. Recall that we take user inputs for adjectives, topic_phrases, branded_phrases, and final_url. These can now all be substituted given our tokenized textual extracts.
We firstly expand our list of adjectives by appending the values stored in positive_adjectives. We will also transform our list of positive adjectives to match the title case requirement of our copy, along with correcting some whitespace formatting to match our future data frame.
adjectives = ['Quality', 'High Quality', 'Excellent', 'Great Quality']adjectives.extend(positive_adjectives)
adjectives = [adjective.title() for adjective in adjectives]
adjectives = [adjective + ' ' for adjective in adjectives]
The variable topic_phrases no longer requires user input as it was identified by our POS tags as most.common_noun. Once again, we will format this variable to match our copy’s title case formatting.
In most marketing activations, we would refer to a product assortment in the plural form. Here, we provide a conditional argument that pluralizes the respective most.common_noun if it does not end in the character "s".
topic_phrases = most_common_noun.capitalize()
suffix = "s"
if topic_phrases.endswith(suffix) == False:
topic_phrases = str(topic_phrases + suffix)The variable branded_phrases no longer takes user input as we were able to identify the brand of the washer using our NER module. We add a space at the end of this variable’s string to ensure formatting consistency and legibility.
branded_phrases = most_common_entity + ' 'Lastly, the final_url variable will require no user input as this is the URL we began with upon parsing our webpage — the value is store in our first instantiated variable, url.
final_url = urlWe’re all done — let’s run and view the results! (Note: I’ve transposed the .CSV output to make it easier to read)
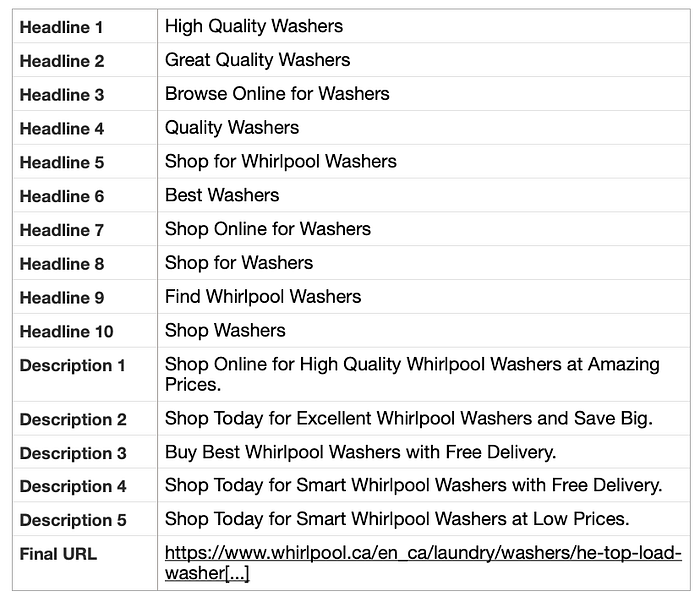
Let’s try it out on another landing page for a 36-inch Wide Counter Depth 4 Door Refrigerator and see what happens.
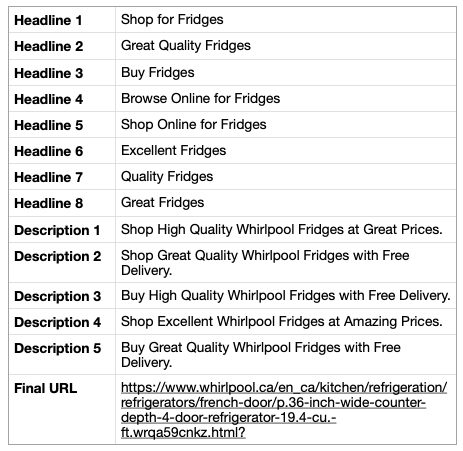
We were able to identify once again the correct lexical elements.
OUTPUT#webpage subject identification
The most common noun is: fridge or Fridge#webpage entity identification
The most common entity is: Whirlpool#adjectives matched to our most common noun
The relevant adjectives are: ['new', 'current', 'Great', 'old', 'Great']#relevant adjective sentiment analysis
new Sentiment(polarity=0.1, subjectivity=0.4)
current Sentiment(polarity=0.0, subjectivity=0.4)
Great Sentiment(polarity=0.8, subjectivity=0.75)
old Sentiment(polarity=0.1, subjectivity=0.2)The positive adjectives are: ['new', 'Great', 'old']#'old' in this case is associated to be very slightly positive.
For more strict parsing of polarity, increase the threshold of acceptance (if TextBlob(adjective).sentiment.polarity > 0:)
We’ve come to the end of our NLP journey — thanks for reading! I hope you’ve found this guide useful in automating some of your marketing tactics. As always, the full source code is available via my gitHub repository — https://github.com/rfinatan/Natural-Language-Processing-for-Marketing-and-E-Commerce-Using-spaCy.
You can also find more similar projects on my portfolio page. If you’d like to connect, please feel free to add me on LinkedIn.
